Reinforcement Learning Projects
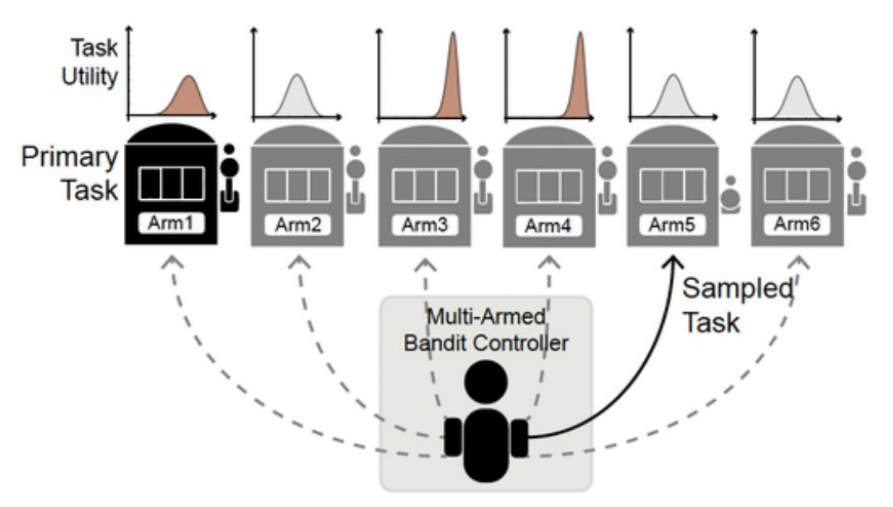
In this project, I give a brief introduction on the Multi-armed Bandits problem, I experiment with multiple approaches to solve it and I compare the results. I also introduce the Contextual Bandits problem.
The environment used to train the agents has 10 actions representing routes to go from work to home and it returns as reward the time spent in traffic in that route. The goal of the agents is to find the fastest route (in expectation).
Created on: April 10, 2023 Last modified: April 10, 2023
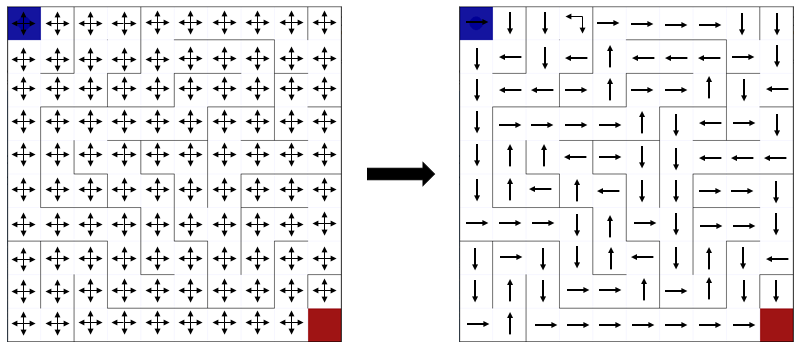
In this project, I introduce a few concepts that are the foundations to more advanced RL algorithms, such as an MDP, value functions and Bellman Equations. Then, I solve the maze problem using dynamic programming: Policy Iteration, Value Iteration and Generalized Policy Iteration.
The environment used to train the agents was taken from this github repository and a few adaptations were made.
Created on: June 12, 2023 Last modified: June 12, 2023
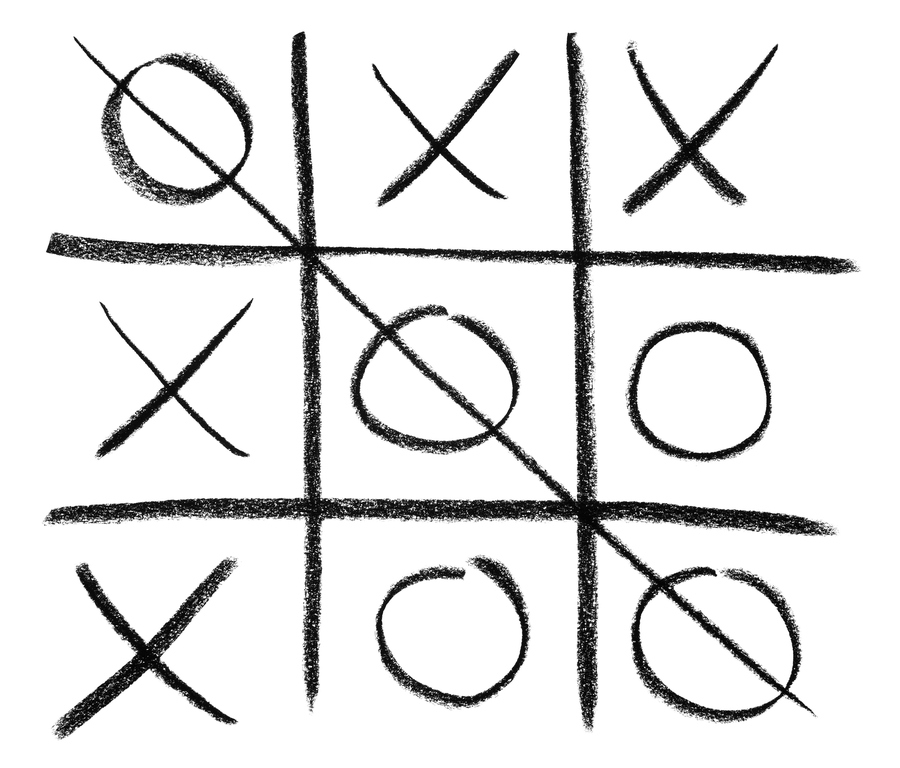
In this project, I introduce Monte Carlo methods for estimating value functions, as well as different strategies of exploration of the state-action space. I also explain the concept of an after-state and how it is useful. Finally, I train an agent to learn how to play Tic Tac Toe against a random opponent and an advanced one.
The Tic Tac Toe environment used to train the agents was built from scratch and has the options of a random or advanced opponent to play with.
Created on: August 14, 2023 Last modified: August 14, 2023
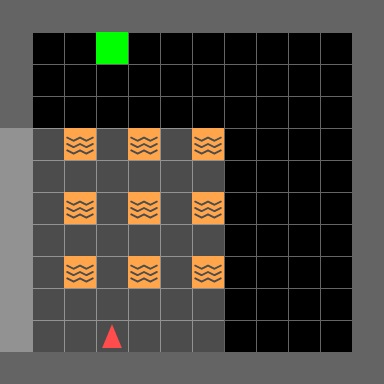
In this project, I extend the Monte Carlo algorithms to the off-policy setting and I introduce different methodologies, such as Ordinary and Weighted Importance Sampling, Discount-Aware Importance Sampling and Per-Decision Importance Sampling.
The environment used to train the agents is a customized version of the Mini-grid environment from the Farama Foundation.
Created on: September 29, 2023 Last modified: September 29, 2023
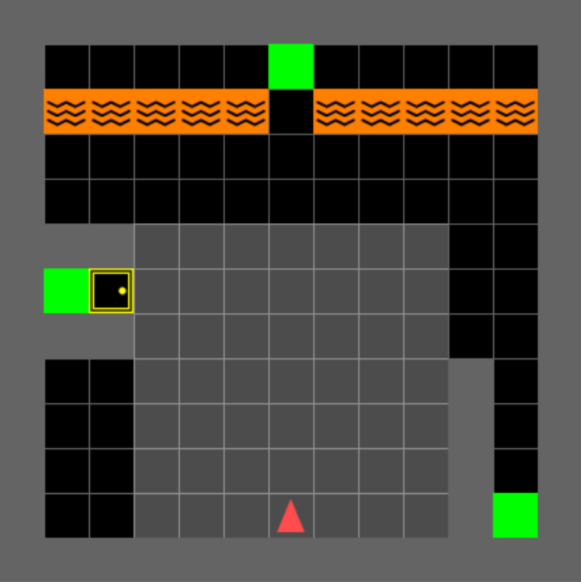
In this project, I talk about Temporal Difference methods to learn an optimal policy. More specifically, I compare different algorithms of the class of TD(0) methods, such as Sarsa, Expected Sarsa, Q-Learning and Double Q-Learning.
The environment used to train the agents is a customized version of the Mini-grid environment from the Farama Foundation.
Created on: March 12, 2024 Last modified: March 12, 2024

In this project, I unify Monte Carlo and TD Learning by introducing n-Step TD Learning.
I compare this algorithm on multiple values of n, both on and off-policy, using the Taxi environment from the Farama Foundation to train the agents.
Created on: August 29, 2024 Last modified: August 29, 2024
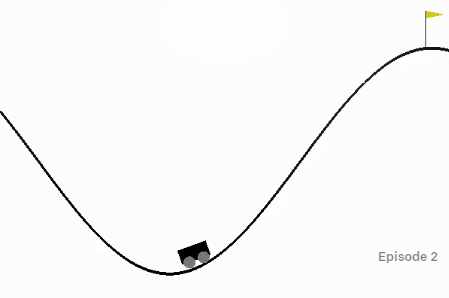
The goal of this challenge is to drive the car up the mountain on the right and pass the yellow flag. However, the car's engine is not strong enough to reach the top of the hill by itself. Therefore, the only way to succeed is to drive back and forth to build up momentum.
In this project, I applied reinforcement learning algorithms to find an optimal policy for the car to control its engine power in order to reach the yellow flag the fastest way possible. I start by using tabular Q-learning with state aggregation, followed by linear function approximation methods.
The environment with the mountain and car can be found at the Gymnasium website.
Created on: April 11, 2020 Last modified: April 11, 2020